When working in Python, there are times when you have cpu-bound processing and need real threads. These are times to reach for C. The interop between the languages is clean, minimal, and fast. Here, I’ll give a quick example with a little commentary to assist with understanding the basics. First, the basic problem. How doContinue reading “Wrapping C APIs in Python”
Author Archives: jclosure
EventBusBridges for Great Good
The SockJS protocol provides a fast and reliable mechanism for providing duplex communication via Websockets. Vertx has a particularly nice implementation of this in the form of EventBusBridges, which make it easy to create secure communication pipelines between an HttpServer Verticle and a variety of polyglot SockJS clients via Websockets or fallback transports. Surprisingly, a Java-basedContinue reading “EventBusBridges for Great Good”
How To Cleanly Integrate Java and Clojure In The Same Package
A hybrid Java/Clojure library designed to demonstrate how to setup Java interop using Maven This is a complete Maven-first Clojure/Java interop application. It details how to create a Maven application, enrich it with clojure code, call into clojure from Java, and hook up the entry points for both Java and Clojure within the same project.Continue reading “How To Cleanly Integrate Java and Clojure In The Same Package”
The Mind Think and Practice of Designing Testable Routing
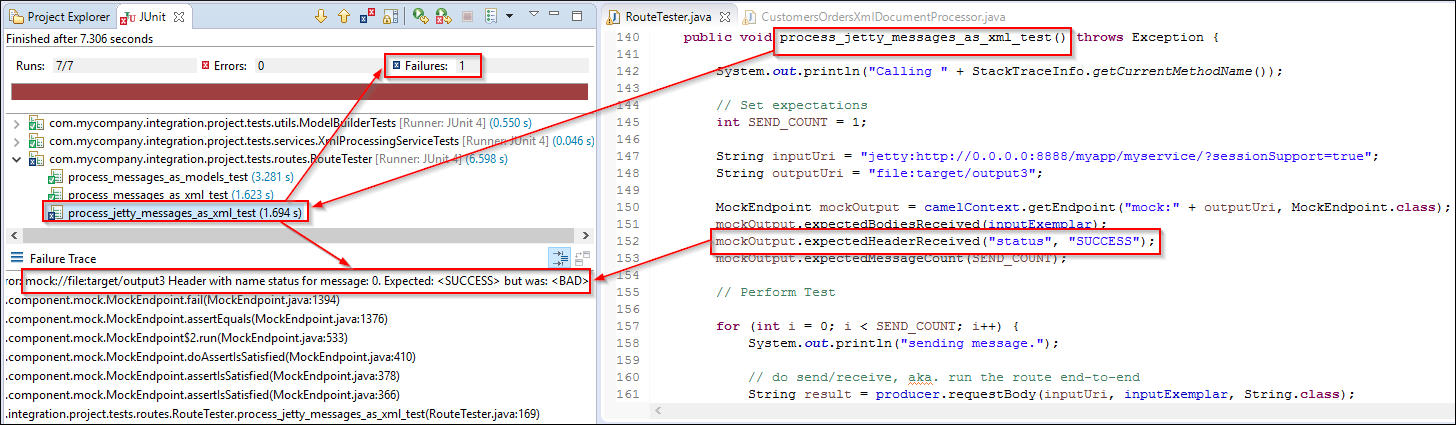
Integrating applications, data, and automated workflow presents a uniquely entrenched set of dependencies for software developers. The need for an endpoint to exist in order to integrate with it seems basic and undeniable. Additionally, the data that an endpoint produces or consumes needs be available for the integration to work. It turns out that theseContinue reading “The Mind Think and Practice of Designing Testable Routing”
Integrating JBoss Fuse ESB with Active Directory
As of the time of this writing, I could not find a documented recipe for using Active Directory as the authentication and authorization backend of JBoss Fuse ESB. Here’s a link to the official documentation on Enabling LDAP Authentication. It describes how to integrate with Apache Directory Server, which has some key differences from MicrosoftContinue reading “Integrating JBoss Fuse ESB with Active Directory”
Defining Log4j MDC Fields Declaratively With Spring
In this post, I’m going to show you how to extend the fields Log4j captures via MDC (Mapped Diagnostic Contexts). Specifically, we will add an additional field called “ApplicationId” that will identify the application that a given log entry came from. This is useful when you have many applications logging to a single persistence mechanism.Continue reading “Defining Log4j MDC Fields Declaratively With Spring”
Surfing the ReferencePipeline in Java 8
Java 8 includes new a Stream Processing API. At its core is the ReferencePipeline class which gives us a DSL for working with Streams in a functional style. You can get an instance of a ReferencePipeline flowing with a single expression. The MapReduce DSL has the essential set of list processing operations such as querying,Continue reading “Surfing the ReferencePipeline in Java 8”
Grokking JBoss Fuse Logs with Logstash
JBoss Fuse or more generally Apache ServiceMix ship with a default log4j layout ConversionPattern. In this article I will show you how to parse your $FUSE_HOME/data/log/fuse.log file, collect its log entries into Elasticsearch, and understand whats going on in the Kibana UI. First a few pieces of context. If you are not familiar with theContinue reading “Grokking JBoss Fuse Logs with Logstash”
Accepting Invalid SSL Certificates in .NET WCF Clients
There are times when SSL certificates are used to verify identity and to provide TLS and there are cases when only the wire encryption matters. In the later case, I sometimes need to be able handle server certificates that are not valid by SSL’s standard rules. This could be because the cert is not signedContinue reading “Accepting Invalid SSL Certificates in .NET WCF Clients”
NTLM Authentication in Java with JCifs
In enterprise software development contexts, one of the frequent needs we encounter is working with FileSystems remotely via CIFS, sometimes referred to as SMB. If you are using Java in these cases, you’ll want JCifs, a pure Java CIFS implementation. In this post, I’ll show you how to remotely connect to a Windows share on an ActiveContinue reading “NTLM Authentication in Java with JCifs”
